"Gzip beats BERT?" Part 2: dataset issues, improved speed, and results
Published 2023 / 07 / 28 [later minor updates]

Summary: Update to my last post analyzing the gzip+knn paper. Some of the datasets have heavily contaminated train/test tests. I show some ways to significantly speed-up the gzip method. I present more results of my "fair" reimplementation.
Last week I wrote
my analysis
of the code
for the paper
"Low-Resource" Text Classification: A Parameter-Free Classification Method with Compressors.
The paper proposed a text classification method using
gzip + kNN and gained some attention on twitter by showing this "simple"
method beat many benchmarks, including language models like BERT.
It turns out that the classification method used in their code looked at the test label as part of the decision method and thus led to an unfair comparison to the baseline results. You can read the discussion with the author on this github issue. They confirmed that this was not a bug, but a way to compute the maximum possible accuracy for a stochastic classifier (choosing one of the top-2 nearest neighbors). I claim that this too unfairly inflates their method’s results against the baselines. Also, it’s unnecessary: you can use a stochastic classifier and present the average (and possibly more stats like min, max, std, etc.) over repeated trials.
In this post I describe another major problem that
someone discovered: some of the datasets have heavily
contaminated train/test sets. I also show
some ways to greatly speed up the gzip-based method,
and I present more complete results using
what I consider a "fair" accuracy calculation.
Contents
1. Dataset issues
At the end of my previous post, I included a brief
to-do note: "Why is filipino so high (1.0 in one case)?",
referring to one dataset (DengueFilipino) having suspiciously high accuracy.
My attempt to run the official code
gave 100% accuracy. The paper reported 99.8% (Table 5).
Before I got around to looking at that, someone
else discovered and reported the problem (see the
github issue) - the filipino dataset has exactly equal train and test tests! Other datasets also have
significant train/test contamination.
There are also duplicate data points.
1.1. Details
Here are the statistics I computed for all the datasets:
| train set | test set | train-test intersection | ||||||
|---|---|---|---|---|---|---|---|---|
| name | count | unique | %dup | count | unique | %dup | count | % of test |
| AG_NEWS | 120000 | 120000 | 7600 | 7600 | 0 | |||
| DBpedia | 560000 | 560000 | 70000 | 70000 | 0 | |||
| YahooAnswers | 1400000 | 1400000 | 60000 | 60000 | 0 | |||
| 20News | 11314 | 11314 | 7532 | 7532 | 0 | |||
| ohsumed | 3357 | 3357 | 4043 | 4043 | 0 | |||
| R8 | 5485 | 5427 | 1.1% | 2189 | 2176 | 0.6% | 4 | 0.2% |
| R52 | 6532 | 6454 | 1.2% | 2568 | 2553 | 0.6% | 6 | 0.2% |
| KinyarwandaNews | 17014 | 9199 | 45.9% | 4254 | 2702 | 36.5% | 643 | 23.8% |
| KirundiNews | 3689 | 1791 | 51.5% | 923 | 698 | 24.4% | 631 | 90.4% |
| DengueFilipino | 4015 | 3951 | 1.6% | 4015 | 3951 | 1.6% | 3951 | 100.0% |
| SwahiliNews | 22207 | 22207 | 7338 | 7338 | 34 | 0.5% | ||
| SogouNews | 450000 | 450000 | 60000 | 60000 | 0 | |||
The paper’s repo does minimal processing on the datasets. It turns out that these problems exist in the source Huggingface datasets. The two worst ones can be checked quickly using only Huggingface’s datasets.load_dataset:
>>> from datasets import load_dataset
>>> import numpy as np
>>> # train == test
>>> ds = load_dataset("dengue_filipino")
>>> print(list(ds['train']) == list(ds['test']))
True
>>> # 90% overlap:
>>> ds2 = load_dataset('kinnews_kirnews', 'kirnews_cleaned')
>>> keys = sorted(ds2['test'][0].keys())
>>> set_train = set([tuple([item[key] for key in keys]) for item in ds2['train']])
>>> set_test = set([tuple([item[key] for key in keys]) for item in ds2['test']])
>>> print(np.mean([a in set_train for a in set_test]))
0.9040114613180515
1.2. Ambiguous data points
Of course, having test points that
are in your training data
will artificially raise the
accuracy for all classifiers. But,
it is particularly beneficial
for kNN - a point’s nearest neighbor will be
itself and we should get everything perfectly correct
(as opposed to neural network
classifiers that typically have some
amount of training error).
So, how did the DengueFilipino tests
have below 100% accuracy for kNN?
As I mentioned, my re-running
of the official code gave 100%, so I’m not
sure how they got the 99.8% in Table 5.
My kNN(k=1) classifier got 99.9%
accuracy (5 errors out of 4015), so let’s
look at the five test points it got wrong:
| test point | closest train point | |||
|---|---|---|---|---|
| index | text | label | text | label |
| 1269 | "Broken heart syndrome ?" | 4 | "Broken heart syndrome ?" | 2 |
| 2363 | "Monday sickness ?" | 4 | "Monday sickness ?" | 0 |
| 2441 | "Monday sickness ?" | 4 | "Monday sickness ?" | 0 |
| 2677 | "Monday sickness ?" | 2 | "Monday sickness ?" | 0 |
| 3440 | "playsafe, u ain't sick ?" | 4 | "playsafe, u ain't sick ?" | 2 |
So, the dataset has repeated texts with different
ground-truth labels.
Note, this is different from the dup (duplicates)
column in the above table, which was counting
duplicates of the (data,label) tuples. In the kNN, these
duplicates have equal distances, and in these cases,
it happened to select the wrong ones.
Someone with knowledge of the dataset will have to determine if this is a preparation error or an actual desired property. If it’s the latter, perhaps a different scoring criterion could be used (of course, followed by all compared methods).
2. Speed Improvements
In trying to recreate the baseline results,
you will quickly learn that the gzip + kNN
method is slow for datasets
with a large training set.
The costly computation is the distance
matrix containing num_train × num_test elements.
In the paper’s codebase, there is a
calc_dis method here and
if we remove the abstractions and
remove some of the unused options,
we see it doing the following:
#test_data:[str]
#train_data:[str]
#clen: compute the compressed-length of data:
clen = lambda data : len(gzip.compress(data))
# NCD: Normalized Compression Distance
# distance function
NCD = lambda c1, c2, c12 : (c12 - min(c1,c2)) / max(c1, c2)
for i,t1 in enumerate(test_data):
l1 = clen(t1.encode('utf8'))
for j,t2 in enumerate(train_data):
l2 = clen(t2.encode('utf8'))
l12 = clen( (t1 + ' ' + t2).encode('utf8') )
D[i,j] = NCD(l1,l2,l12) # fill distance matrix
2.1. Repeated work
We can quickly see a few things are being unnecessarily repeated,
There are a few repeated
str.encode(). We can start by converting everything to bytes.The computation of
l2is in the inner loop, but does not depend on the test data (t1). We should pre-computel2for the whole training set only once.
So, now we have something like,
train_data = [a.encode('utf8') for a in train_data]
test_data = [a.encode('utf8') for a in test_data]
train_lengths = [clen(t2) for t2 in train_data]
for i,t1 in enumerate(test_data):
l1 = clen(t1)
for j,t2 in enumerate(train_data):
l2 = train_lengths[j]
l12 = clen( (t1 + b' ' + t2) )
D[i,j] = NCD(l1,l2,l12)
I don’t have the exact speed-up numbers on this step right
now, but I think it is pretty significant.
For example, YahooAnswers dataset
has 1.4 million training samples and 60 thousand test samples.
So, in the original code, for each of the 60 thousand test
points, it was recomputing the clen() for each of the 1.4 million
training documents every time.
2.2. gzip / zlib tricks
Another case of repeated computation: we compress t1
(the test point), but
then in the inner-loop, we compress it again (as
the start of the larger string t1 + " " + t2).
Can we remove this rendancy? Yes we can!
First, the relationship between a few related terms: GZIP is a file format for holding compressed data. The data is compressed with the DEFLATE algorithm. zlib is a library that implements DEFLATE and has it’s own lower-level format for compressed data.
So, gzip is simply a small
wrapper around zlib.
You can see this clearly in Python’s source code
for the gzip.compress(x) function [here]:
it simply returns header + zlib.compress(x) + footer.
[So maybe instead of the headline "gzip beats BERT?" it should be "zlib beats BERT?" or "DEFLATE beats BERT?"]
We want to compress a string (test point t1) with zlib, then continue that compression with different training points (t2). Luckily Python’s
zlib module provides the exact interface we need: a compressobj that stores the state of the zlib compressor and a copy method to copy its state.
The Python docs for copy()
even mention our use-case: Compress.copy(): Returns a copy of the compression object. This can be used to efficiently compress a set of data that share a common initial prefix.
I implemented this in a class called GzipLengthCalc. Using this, the main loop is now,
for i,t1 in enumerate(test_data):
#starts compressing 't1 + b" "'
g = GzipLengthCalc(t1)
l1 = g.length1
for j,t2 in enumerate(train_data):
l2 = precomputed_lengths[j]
# continues from stored zlib state to
# compress t2:
l12 = g.length2(t2)
D[i,j] = NCD(l1, l2, l12)
Keep in mind that the inner-loop is run billions of times for some of the datasets, so removing anything there can be a huge speed up.
Any more room for improvement?
I tried removing more of the
NCDcalculation from the inner loop. The loops can compute the matrix of distances, and we compute theNCDoutside of the loops using vectorized numpy,D = (C12 - np.minimum(C1,C2)) / np.maximum(C1,C2). This had a small speed improvement, but at the memory cost of allocated 3 matrices instead of 1, so I didn’t use that.Is it possible that precomputed
clen(t2)can speed up the computation ofclen(t1 + b' ' + t2)? Probably not.zlibworks sequentially. Perhaps, with some realzlibwizardry: there are internal parameters like a "block size" such that the past bytes a certain distance before the current point no longer matter. Perhaps this could be exploited in the case of large texts.If more significant gains were wanted, I’d suggest computing this double-loop in C.
2.3. Multiprocessing
The original code had some support for multiprocessing.
I expanded this using concurrent.futures and made it flexible to parallelize to the number of workers using os.cpu_count().
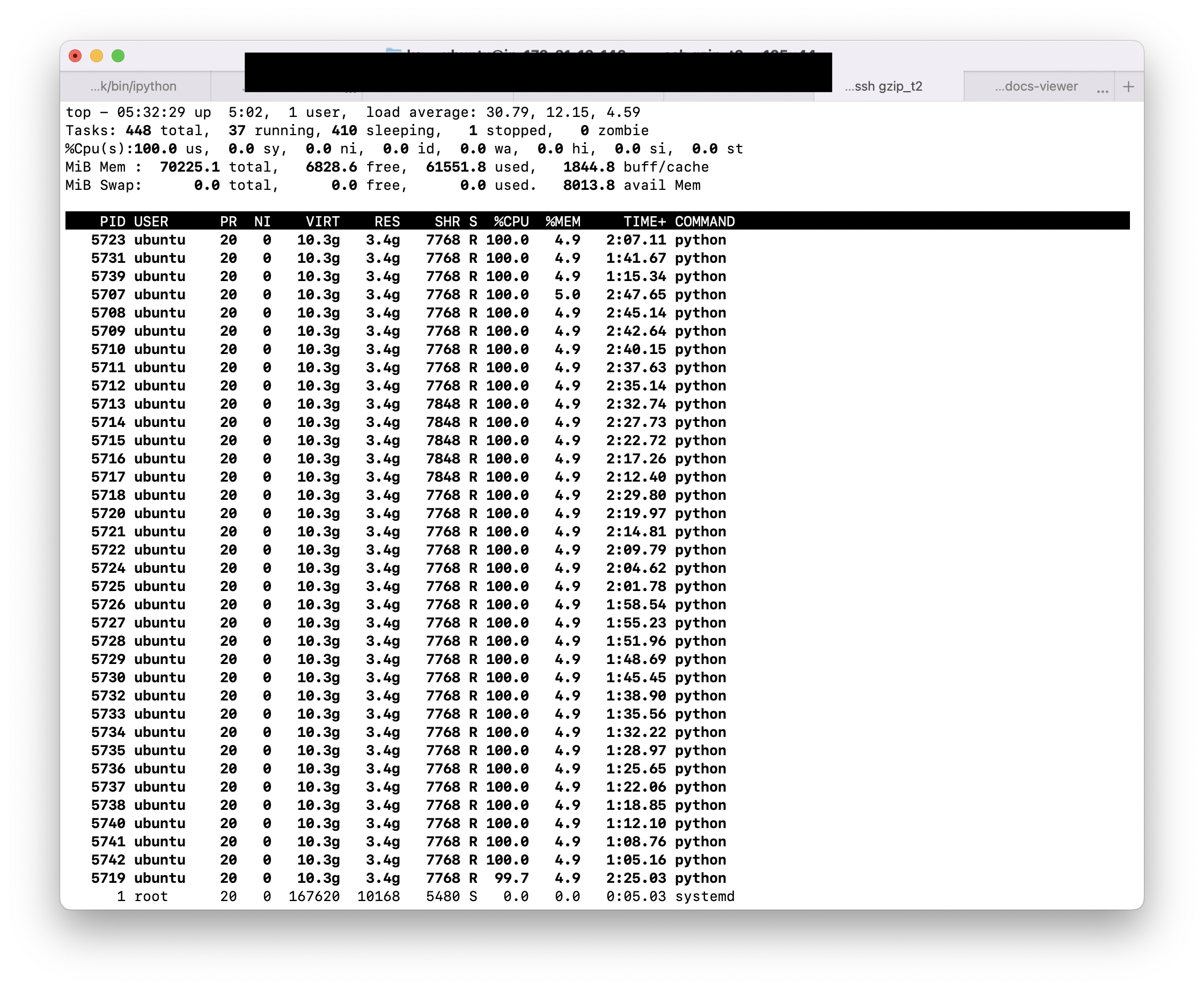
For example, if you run a machine with 36 vCPUs, you can get 36 Python processes all running at 100% as shown below.
So, who cares about the GIL? Well, as-is, the multiprocessing has quite a bit of overhead in passing around large amounts of data to the child processes. This could be improved.
3. Results
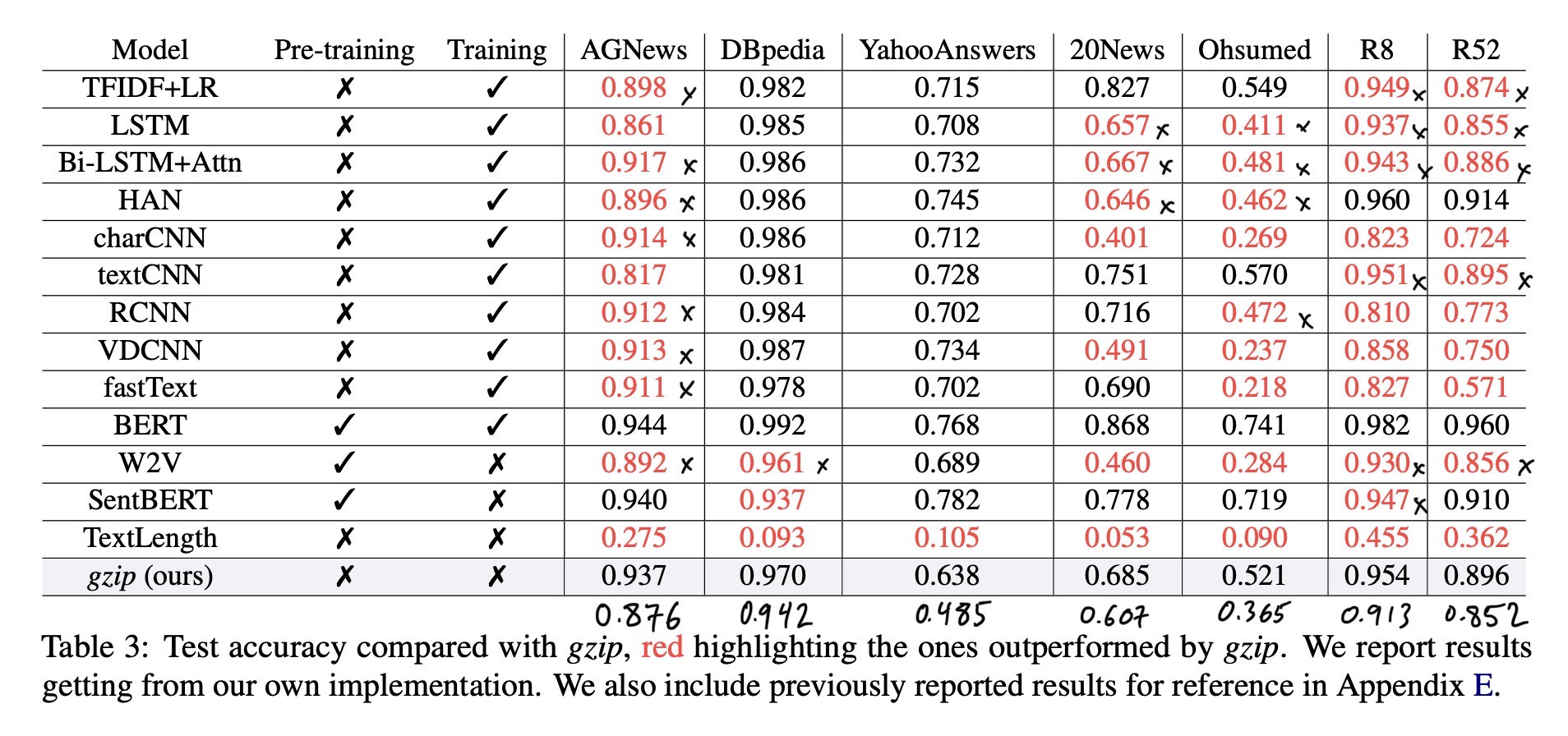
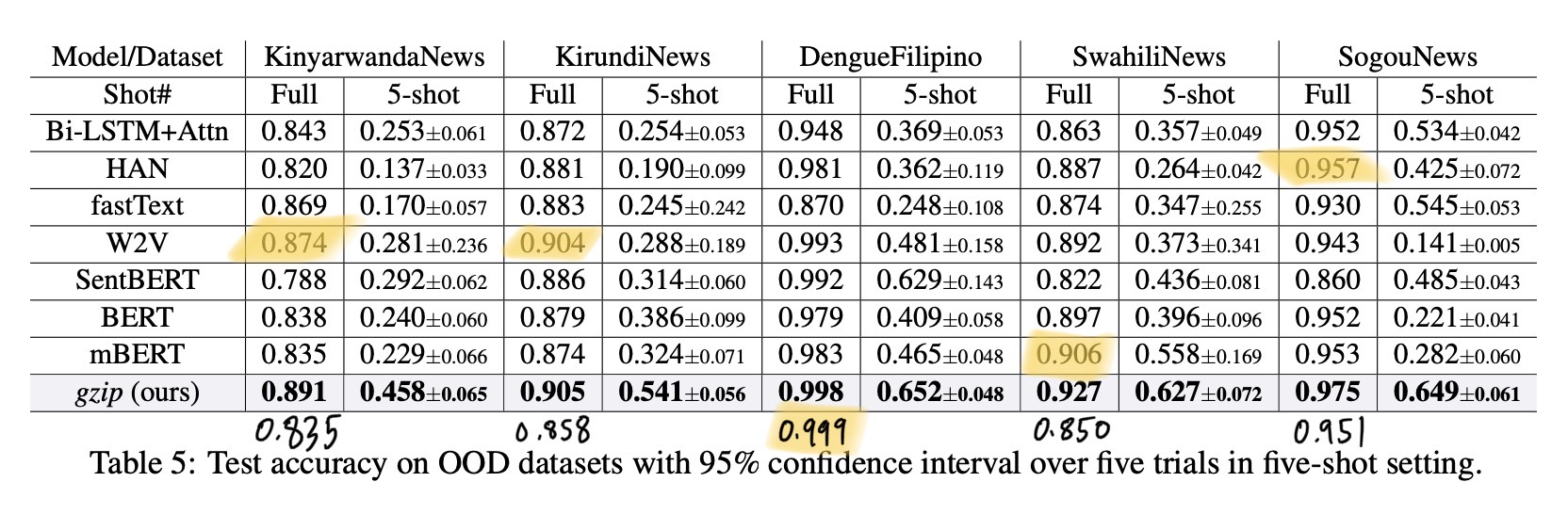
With these speed improvements, I could run my implementation across all the datasets. I present results below along with the comparable results from the paper, Table 3 and Table 5.
The rows in my results table are:
paper: Copied value from the paper (Table 3 and Table 5).
rerun: My run of the (code) provided by the authors. The blanks in this row mean it was too slow, and I didn’t finish it.
top2: My implementation, with top-2 accuracy.
kNNthat is marked correct if either of the top-2 nearest neighbors are correct.knn1: My implementation, standard
kNNwithk=1, i.e. just taking the label of the single nearest neighbor.
| AGNews | DBpedia | YahooAn. | 20News | Ohsumed | R8 | R52 | |
|---|---|---|---|---|---|---|---|
| paper | 0.937 | 0.970 | 0.638 | 0.685 | 0.521 | 0.954 | 0.896 |
| rerun | 0.685 | ||||||
| top2 | 0.937 | 0.970 | 0.622 | 0.685 | 0.481 | 0.952 | 0.889 |
| knn1 | 0.876 | 0.942 | 0.485 | 0.607 | 0.365 | 0.913 | 0.852 |
| KinyarwandaNews | KirundiNews | DengueFilipino | SwahiliNews | SogouNews | |
|---|---|---|---|---|---|
| paper | 0.891 | 0.905 | 0.998 | 0.927 | 0.975 |
| rerun | 0.891 | 0.906 | 1.000 | 0.927 | |
| top2 | 0.891 | 0.906 | 1.000 | 0.927 | 0.973 |
| knn1 | 0.835 | 0.858 | 0.999 | 0.850 | 0.951 |
3.1. Notes
The following 3 rows should all have the same value: paper, rerun, and top2. As in my previous blog post, that confirms that the paper used a non-comparable top-2 accuracy metric and I was able to recreate it. There are a few cases where these 3 are not the same:
The three datasets: Ohsumed, R8, and R52 are the three datasets that are not automatically prepared by the
npc_gziprepo [see issue]. It is very possible that I am using a slightly different dataset than the original paper.YahooAnswersdataset. Not sure whypaper = 0.638andtop2 = 0.622.DengueFilipinois very close. This was the one where training test equals test set.
Differences could be due to different ordering of the data points (which can effect ties in distance value; as opposed to ties in label votes).
In the table images, I wrote the knn1 scores below the table. When using these as the gzip results, we generally don’t see improvement compared to baseline methods.
For now, I only have the k=1 results here. My last post showed a handfull of different k values and methods for breaking ties. In those results, there was no clear winner across datasets. Results with different k can be seen in results.txt in the github repo of my implementation.
4. Conclusions
Between the accuracy calculation and contaminated datasets, I believe that many of the key results (and thus also the conclusions) in the paper are not valid.
The paper touts kNN + gzip as computationally
simpler than language-model-based methods,
but beware that it is slow for the datasets
with large amount of training samples.
Nevertheless, using ideas from text compression for text classification tasks is an interesting idea and may lead to other interesting research.
4.1. Links
gzip-knn: my re-implementation
Related work people have sent me,